راهکار ذخیره سازی برای متخصصان هوش مصنوعی

امنیت







فهرست مطالب
راهکار ذخیره سازی
توسعهدهندگان به سمت فناوریهایی گرایش پیدا میکنند که نرمافزار محور، متن باز، مبتنی بر ابر و ساده باشند. به بیان سادهتر، ما در حال ورود به عصری هستیم که مبتنی بر ذخیره سازی ابرمحور و معماری شیمحور است.
انتخاب بهترین فضای ذخیرهسازی برای تمام مراحل یک پروژه یادگیری ماشین (ML) بسیار مهم است. پژوهشگران، نیاز به ساخت چند نسخه از مجموعه دادهها و آزمایش آنها با معماریهای مختلف دارند تا در نهایت مدلی متناسب با نیازهای تجاری انتخاب شود. هنگامی که مدل نهایی انتخاب و ارتقا داده میشود، باید توانایی پیشبینی اتفاقات آینده بر مبنای دادههای جدید را با بالاترین ضریب دقت داشته باشد. یک مدل آموزشدیده دقیق که بر مبنای مباحث مهندسی دقیق پیادهسازی شده باشد، به روشهای متنوع در بخشهای مختلف یک صنعت مورد استفاده قرار میگیرد. این هدفی است که تیمهای توسعهدهنده مدلهای هوشمند به دنبال آن هستند. در این راهنمای کاربردی، همه چیز از انواع سیستمهای فایل سنتی تا مخازن ذخیرهسازی ابرمحور که باهدف پاسخگویی به نیازهای کارکردی مدلهای زبانی بزرگ (LLM) و سایر سیستمهای هوش مصنوعی مورد استفاده قرار میگیرند را بررسی خواهیم کرد. پس از درک الزامات و گزینههای ذخیرهسازی، هر مورد را بررسی خواهیم کرد تا ببینیم چگونه با الزامات ما مطابقت دارد. قبل از اینکه وارد الزامات شویم، بررسی آنچه امروز در صنعت نرمافزار در حال رخ دادن است خالی از لطف نیست.
وضعیت فعلی یادگیری ماشین و هوش مصنوعی
مدلهای زبانی بزرگ که میتوانند با دقتی نزدیک به انسان صحبت کنند، بر رسانهها تسلط یافتهاند. این مدلها برای آموزش به حجم زیادی از دادهها نیاز دارند. پیشرفتهای هیجانانگیز دیگری نیز در زمینه هوش مصنوعی مولد رخ داده است. بهطور مثال، تبدیل متن به تصویر و صدا که امروزه سرویسهای مختلفی بر پایه این مفهوم به شکل تجاری مورد استفاده قرار میگیرند. این سرویسها در یک نقطه وجه اشتراک دارند، همگی به حجم زیادی از دادهها نیاز دارند.
فراتر از مدلهای زبانی بزرگ (LLM)
فراتر از مدلهای زبانی بزرگ که در اخبار جنجال به پا کردهاند، انواع دیگری از مدلها نیز وجود دارند که مشکلات اساسی کسبوکارها را حل میکنند. رگرسیون، طبقهبندی و چندبرچسبی، نمونههایی از مدلهای غیرمولد هستند که ارزش افزوده قابل توجهی در اختیار سازمانها قرار میدهند. بههمین دلیل است که سازمانهای بیشتری به دنبال این نوع مدلها برای حل طیف وسیعی از مسائل خود هستند.
یکی دیگر از پدیدههای در حال ظهور، افزایش تعداد شرکتهایی است که تمایل دارند بهعنوان ارائهدهندگان خدمات نرمافزاری تحت مدل SaaS خود را به دنیای تجارت معرفی کنند و خدمات آموزش مدلها را با استفاده از دادههای خصوصی مشتریان خود ارائه میدهند. بهعنوان مثال، تصور کنید، مهندسی، یک مدل زبانی بزرگ را با استفاده از دادههای موجود در اینترنت و چند هزار کتاب برای پاسخ به سوالات، مشابه ChatGPT، آموزش داده است. این مدل زبانی عمومی، یک مدل عمومیگرا خواهد بود که قادر به پاسخگویی به پرسشهای اساسی در حوزههای مختلف است.
با این حال، اگر کاربری سوالی بپرسد که نیازمند دانش عمیق در یک صنعت خاص مانند مراقبتهای بهداشتی، خدمات مالی یا خدمات حرفهای است، ممکن است این مدل زبانی بزرگ پاسخ مفید، دقیق و کاملی ارائه نکند. راهحل این است که مدل آموزشدیده را با دادههای اضافی مرتبط با صنعت، تنظیم دقیق (fine-tune) کرد.
بنابراین، یک مدل زبانی بزرگ آموزشدیده بهعنوان مدل عمومیگرا را میتوان با دادههای خاص صنعت، به شکل تخصصیتر آموزش داد. سپس مدل، پاسخهای بهتری به سوالات مربوط به صنعت موردنظر ارائه خواهد کرد. تنظیم دقیق به ویژه برای مدلهای زبانی بزرگ مفید است، زیرا آموزش اولیه آنها میتواند میلیونها دلار هزینه داشته باشد، اما طراحی مبتنی بر «تنظیم دقیق» بسیار ارزانتر است.
صرفنظر از نوع مدلی که میسازید، پس از راهاندازی باید در دسترس، مقیاسپذیر و انعطافپذیر باشد، درست شبیه به برنامههای کاربردی یا سرویسهایی که طراحی میکنید و در اختیار کاربران نهایی قرار میدهید. اگر کسبوکاری دارید که راهحل SaaS ارائه میدهید، الزامات امنیتی را نباید نادیده بگیرید. به بیان دقیقتر، شرکتها باید بر مبنای یک مکانیزم احراز هویت دقیق و روش پرداخت مشخص به مدل شما دسترسی داشته باشند تا بتوانید مزیت رقابتی خود را حفظ کنید و همچنین باید به شکل دقیقی از دادههای مشتریان خود محافظت کنید. برای درک بهتر موضوع اجازه دهید با جزئیات بیشتر به این الزامات نگاه کنیم.
الزامات ذخیره سازی یادگیری ماشین
الزامات ذخیرهسازی که در زیر فهرست شدهاند، از دیدگاه یک تصمیمگیرنده فنی که قابلیت بالقوه هر فناوری را ارزیابی میکند، مورد بررسی قرار میگیرند. به طور خاص، فناوریهای به کار رفته در یک راهحل نرمافزاری باید مقیاسپذیر، در دسترس، امن، کارآمد، انعطافپذیر و ساده باشند. اجازه دهید تا به بررسی این موضوع بپردازیم که هر یک از این الزامات برای یک پروژه یادگیری ماشین به چه معنا است؟
مقیاسپذیری (Scalability)
مقیاسپذیری در یک راهکار ذخیره سازی به توانایی آن در مدیریت حجم فزایندهای از دادهها بدون نیاز به تغییرات قابل توجه اشاره دارد. بهعبارت دیگر، یک راهکار ذخیره سازی مقیاسپذیر باید بتواند با افزایش نیاز به ظرفیت و توان عملیاتی به عملکرد بهینه خود ادامه دهد. فرض کنید سازمانی به تازگی سفر یادگیری ماشین و هوش مصنوعی خود را با یک پروژه واحد آغاز کرده است. این پروژه به تنهایی ممکن است نیاز به فضای ذخیرهسازی زیادی نداشته باشد. با این حال، به زودی تیمهای دیگر پیشنهادهای خود را ارائه خواهند کرد. این تیمهای جدید ممکن است در ابتدای راه نیازهای ذخیرهسازی کمی داشته باشند. اما در گذر زمان به فضای ذخیرهسازی قابل توجهی نیاز خواهند داشت. یک راهکار ذخیره سازی مقیاسپذیر باید به گونهای طراحی شود تا امکان مدیریت ظرفیت و توان عملیاتی اضافی مورد نیاز با ورود دادههای تیمهای جدید را داشته باشد و بتوان به شکل سادهای منابع را به صورت افقی یا عمودی، ارتقا داد.
دسترسپذیری (Availability)
ویژگی مذکور به توانایی یک سیستم عملیاتی برای انجام وظیفه یا وظایف خاص اشاره دارد. کارمندان فناوری اطلاعات یک سازمان به شکل دورهای، دسترسپذیری یک سیستم را در بازههای زمانی مختلف اندازهگیری میکنند. به عنوان مثال، ممکن است گفته شود، سیستم در 99.999 درصد ماه در دسترس بوده است. در این راستا، دسترسپذیری معنای دیگری نیز دارد و به زمان انتظاری که یک کاربر تجربه میکند تا زیرساخت درخواست را پردازش کرده و نتیجه را ارائه دهد، اشاره دارد. زمان انتظار بیش از حد به معنای آن است که سیستم توانایی محدودی در رسیدگی به حجم زیادی از درخواستها دارد.
مهم نیست به کدام تعریف دسترسپذیری اشاره کنیم، این ویژگی، نقش تعیینکنندهای در بحث ذخیرهسازی دادهها و آموزش مدل دارد. آموزش مدل نباید به دلیل عدم در دسترس بودن راهکار ذخیره سازی با تاخیر مواجه شود. یک مدل در حال تولید باید برای 99.999 درصد ماه در دسترس باشد. درخواستهای مربوط به داده یا خود مدل که ممکن است حجیم باشند، باید با صرف زمان کمی در دسترس باشند.
امنیت (Secure)
قبل از هر عملیات خواندن یا نوشتن، یک سیستم ذخیرهسازی باید بداند که شما چه کسی هستید و مجاز به انجام چه کاری هستید. به عبارت دیگر، دسترسی به فضای ذخیرهسازی نیاز به احراز هویت و مجوز دارد. همچنین، دادهها باید در حالت سکون ایمن باشند و راهحل ذخیره سازی گزینههای رمزگذاری را ارائه دهد. فروشنده فرضی SaaS که در بخش قبلی ذکر شد، از آنجایی که خدمات چندمستاجره (multitenancy) را به مشتریان خود ارائه میدهد، باید به امنیت توجه ویژهای داشته باشد. توانایی قفل کردن دادهها، ساخت نسخههای چندگانه از دادهها و تعیین خطمشی نگهداری را مدنظر قرار دهد.
عملکرد (Performance)
یک راهحل ذخیره سازی با عملکرد بالا باید باهدف ارائه توان عملیاتی بالا (throughput) و تاخیر کم، طراحی شده باشد. عملکرد در طول آموزش مدل بسیار مهم است، زیرا عملکرد بالاتر به معنای تکمیل سریعتر آزمایشها است. تعداد آزمایشهایی که یک مهندس یادگیری ماشین میتواند انجام دهد، مستقیما با دقت مدل نهایی مرتبط است. اگر از شبکه عصبی استفاده شود، آزمایشهای زیادی برای تعیین معماری بهینه نیاز است. علاوه بر این، تنظیم ابرپارامترها (hyperparameter tuning) نیازمند آزمایشهای بیشتر است. سازمانهایی که از پردازندههای گرافیکی (GPU) استفاده میکنند، باید مراقب باشند که فضای ذخیرهسازی به گلوگاه (bottleneck) تبدیل نشود. اگر یک راهکار ذخیره سازی نتواند دادهها را با سرعتی برابر یا بیشتر از سرعت پردازش GPU تحویل دهد، سیستم با مشکل اتلاف چرخههای گرانبهای GPU روبرو میشود.
انعطافپذیری / تابآوری (Resilient)
یک راهکار ذخیره سازی انعطافپذیر نباید یک نقطه شکست واحد داشته باشد. یک سیستم انعطافپذیر تلاش میکند تا از خرابی جلوگیری کند، اما هنگامی که خرابی رخ میدهد، باید قابلیت بازیابی ایمن را داشته باشد. چنین راهحلی باید در ارتباط با مسائلی مثل خرابی (failover) و پایداری آزمایش شود و همچنین شبیهسازیهای تخصصی روی آن انجام شود تا هر زمان دسترسی به یک مرکز داده امکانپذیر نبود، امکان استفاده از راهحل ذخیرهسازی وجود داشته باشد. توجه داشته باشید، مدلهایی که در محیط تولیدی اجرا میشوند به انعطافپذیری نیاز دارند. با این حال، انعطافپذیری میتواند در آموزش مدل نیز ارزشآفرین باشد. فرض کنید یک تیم یادگیری ماشین از تکنیکهای آموزش توزیعشده در قالب یک خوشه استفاده میکند. در این صورت، ذخیرهسازی که به این خوشه سرویس میدهد، و همچنین خود خوشه، باید در برابر خطا مقاوم باشند تا تیم به دلیل خرابیها ساعتها یا روزها را از دست ندهد.
ساده (Simple)
مهندسان از کلمات «ساده» و «زیبایی» به صورت مترادف استفاده میکنند. دلیلی برای این موضوع وجود دارد. اگر از یک نرمافزار به شکل ساده و روان استفاده کنید، نشان میدهد که طراحی نرمافزار ساختیافته و دقیق بوده است. طرحهای ساده در سناریوهای مختلف قابل استفاده هستند و مشکلات زیادی را حل میکنند. سیستم ذخیرهسازی برای یادگیری ماشین نیز باید ساده باشد، به خصوص در فاز اثبات مفهومی (PoC) یک پروژه جدید یادگیری ماشین، زمانی که محققان نیاز دارند روی مهندسی ویژگی، معماری مدل و تنظیم ابرپارامترها تمرکز کنند و در عین حال برای بهبود عملکرد تلاش کنند تا مدل به اندازه کافی دقیق شود و ارزش تجاری داشته باشد.
چشمانداز ذخیرهسازی
راهحلهای ذخیرهسازی مختلفی در تعامل با یادگیری ماشین و ارائه مدلهای هوش مصنوعی وجود دارند.
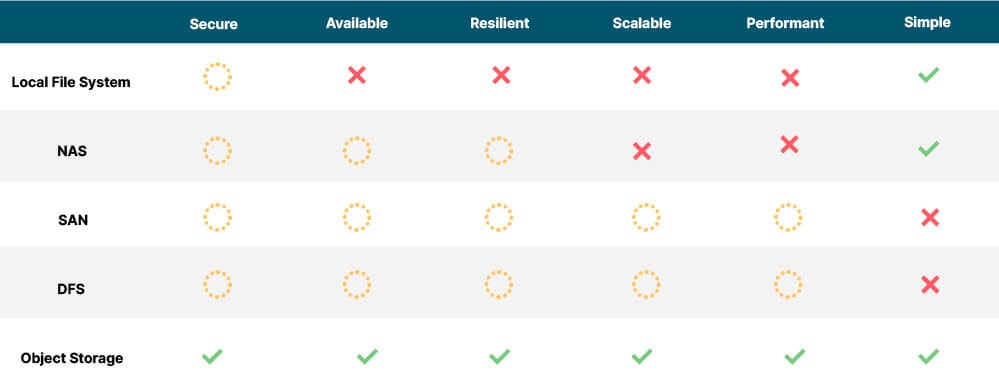
امروزه، گزینههای مذکور در قالب گروههای زیر در دسترس قرار دارند:
- فضای ذخیرهسازی فایل محلی (local file storage)
- ذخیرهسازی متصل به شبکه (NAS)
- شبکههای منطقه ذخیرهسازی (SAN)
- سیستمهای فایل توزیعشده (DFS)
- ذخیرهسازی شی یا به عبارت دقیقتر شیمحور (object storage)
در این بخش، هر گزینه را بررسی و آنها را با الزامات خود مقایسه میکنیم. هدف این است که گزینهای را پیدا کنیم که در همه الزامات بهترین عملکرد را داشته باشد.
فضای ذخیرهسازی فایل محلی (Local File Storage)
سیستم فایل موجود بر روی ایستگاه کاری یک محقق و سیستم فایل روی سروری که به ارائه مدل اختصاص داده شده، نمونههایی از سیستمهای فایل محلی مورد استفاده برای ذخیرهسازی یادگیری ماشین هستند. دستگاه اصلی برای ذخیرهسازی محلی معمولا یک درایو حالت جامد (SSD) است، اما میتواند یک درایو حافظه غیرفرار اکسپرس (NVMe) پیشرفتهتر نیز باشد. در هر دو سناریو، محاسبات و ذخیرهسازی بر روی یک سیستم واحد قرار دارند. این سادهترین گزینه است. همچنین، یک انتخاب رایج در فاز اثبات مفهومی (PoC) است، جایی که یک تیم تحقیق و توسعه کوچک سعی میکند عملکرد یک مدل را از منظر توجیه هزینهها نشان دهد. در حالی که استفاده از این روش رایج است، اما معایبی هم دارد.
سیستمهای فایل محلی، ظرفیت ذخیرهسازی محدودی دارند و برای مجموعه دادههای بزرگ مناسب نیستند. از آنجایی که هیچ تکثیر یا ارتقای خودکار (autoscaling) وجود ندارد، یک سیستم فایل محلی نمیتواند به شکل دسترسپذیر، قابل اعتماد و مقیاسپذیر عمل کند. امنیت آنها به همان اندازه امنیتی است که سیستم میزبان آنها دارد. هنگامی که یک مدل در مرحله تولید قرار میگیرد، گزینههای بهتری نسبت به سیستم فایل محلی برای ارائه مدل وجود دارد.
ذخیرهساز متصل به شبکه (NAS)
استوریجها، تجهیزاتی هستند که پروتکل TCP/IP نقش کلیدی در آنها دارد. این تجهیزات مثل یک کامپیوتر به شبکه متصل شده و دارای آدرس IP هستند. فناوری اصلی در بطن تجهیزات ذخیرهسازی، آرایه چندگانه دیسکهای مستقل (RAID) است و فایلها از طریق TCP به کاربران تحویل داده میشوند. این دستگاهها اغلب به عنوان یک دستگاه یکپارچه (Appliance) ارائه میشوند. به طور معمول، محاسبات مورد نیاز برای مدیریت دادهها و آرایه رید نیز در انکلوژر انجام میشود.
استوریجها از مکانیزمهای امنیتی سطح بالایی برای محافظت از دادهها استفاده میکنند و پیکربندی رید نیز دسترسپذیری و قابلیت اطمینان آنها را به شکل قابل توجهی افزایش میدهد. استوریج برای انتقال دادهها از پروتکلهای انتقال داده مثل SMB سرنام Server Message Block و NFS سرنام (Network File System) استفاده میکند تا TCP را برای انتقال داده کپسولهسازی کند.
در گذشته، استوریجها، در صورت وجود تعداد زیادی فایل با مشکلات مقیاسپذیری روبرو میشدند که دلیل بروز این مشکل، معماری سلسلهمراتب و مسیریابی ساختار ذخیرهسازی پایهای آنها بود. بهطوری که استوریجها تنها توانایی پشتیبانی از چند میلیون فایل را داشتند و حداکثر ظرفیت ذخیرهسازی برای یک استوریج نیز در حدود دهها ترابایت بود. اکنون این مشکل برطرف شده و معماریهایی مثل ذخیرهسازی بلوکمحور و ظرفیتهای ذخیرهسازی در مقیاس پتابایت، این مشکل را برطرف کردهاند.
شبکه منطقه ذخیرهسازی (SAN)
شبکه منطقه ذخیرهسازی (Storage-area network) ترکیبی از سرورها و استوریجها است که بر مبنای یک مکانیزم ارتباطی پرسرعت کار میکنند. با استفاده از SAN، میتوانید ترافیک ذخیرهسازی را با استفاده از پروتکل کانال فیبر (FCP) روی یک کانال فیبر اختصاصی قرار دهید. درخواست انجام یک عملیات روی فایل ممکن است از طریق TCP به یک SAN برسد، اما کل انتقال داده از طریق شبکهای اختصاصی برای انتقال کارآمد دادهها انجام میشود. اگر شبکه فیبر اختصاصی در دسترس نباشد، SAN میتواند از رابط سیستم رایانهای کوچک اینترنتی (iSCSI) استفاده کند که از TCP برای ترافیک ذخیرهسازی استفاده میکند.
راه اندازی یک SAN نسبت به یک دستگاه NAS پیچیدهتر است، زیرا یک شبکه است نه یک دستگاه مجزا. شما برای دستیابی به بهترین عملکرد از یک SAN به یک شبکه اختصاصی جداگانه نیاز دارید. در نتیجه، یک SAN پرهزینه است و نیازمند تلاش قابل توجهی برای مدیریت است.
در حالی که یک SAN ممکن است در مقایسه با یک NAS (عملکرد بهبود یافته و سطوح مشابه امنیتی، دسترسپذیری و قابلیت اطمینان) جذاب به نظر برسد، اما همچنان یک رویکرد مبتنی بر فایل است و مزایا و معایب خاص خود را دارد. بهبود عملکرد به معنای افزایش پیچیدگی و هزینههای اضافی است. البته، شبکههای منطقه ذخیرهسازی دسترسی به فضای ذخیرهسازی در بازه صدها پتابایت را ارائه میدهند.
سیستم فایل توزیع شده (DFS)
یک سیستم فایل توزیع شده (Distributed file system) به گونهای است که روی چند کامپیوتر یا سرور اجرا میشود و به کاربران این امکان را میدهد که به صورت توزیع شده دادهها را ذخیره و به آنها دسترسی پیدا کنند. برخلاف یک سیستم مرکزی واحد، یک سیستم فایل توزیع شده، دادهها را در میان چندین سرور یا انکلوژر توزیع میکند و به کاربران اجازه میدهد به فایلها دسترسی پیدا کرده و آنها را ویرایش کنند، گویی که روی یک سیستم فایل مرکزی واحد در اختیار دارند.
از نمونههای محبوب سیستمهای فایل توزیع شده میتوان به سیستم فایل توزیع شده هادوپ (HDFS)، سیستم فایل گوگل (GFS)، سیستم فایل ارتجاعی آمازون (EFS) و فایلهای آژور اشاره کرد. شبیه به روشهای مبتنی بر فایل که در بالا ذکر شد، در سیستمهای فایل توزیعشده نیز امکان محافظت از فایلها به بهترین شکل وجود دارد، زیرا رابطی که به سیستمعامل ارائه میشود شبیه به یک سیستم فایل سنتی است. این سیستمها در یک خوشه اجرا میشوند که قابلیت اطمینان را فراهم میکند. اجرای آنها در یک خوشه ممکن است در مقایسه با یک شبکه ذخیرهسازی (SAN) توان عملیاتی بهتری ارائه دهند، اما در صورت وجود تعداد زیادی فایل با مشکلات مقیاسپذیری روبرو میشوند.
ذخیرهسازی اشیاء (Object Storage)
ذخیرهسازی اشیاء مدتها است که وجود دارد، اما زمانی انقلاب بزرگی به وجود آورد که آمازون در سال ۲۰۰۶ با سرویس ذخیرهسازی ساده S3 آن را به اولین سرویس AWS تبدیل کرد. ذخیرهسازی اشیا مدرن، بهطور ذاتی ابری است و سایر ارائهدهندگان خدمات ابری نیز به سرعت محصولات خود را به بازار عرضه کردند. به طور مثال، مایکروسافت سرویس Azure Blob Storage را ارائه میدهد و گوگل سرویس Google Cloud Storage را دارد. رابط برنامهنویسی کاربردی S3، استاندارد عملی برای تعامل توسعهدهندگان با فضای ذخیرهسازی و ابر است. همچنین، شرکتهای متعددی وجود دارند که فضای ذخیرهسازی سازگار با S3 را برای ابر عمومی، ابر خصوصی، لبه شبکه (edge) و محیطهای هممکانی (co-located) ارائه میدهند. صرف نظر از اینکه یک مخزن اشیاء در کجا قرار دارد، از طریق یک رابط کاربری RESTful به آن دسترسی پیدا میشود.
مهمترین تفاوت الگوواره فوق با سایر گزینههای ذخیرهسازی این است که دادهها در یک ساختار تخت (flat) ذخیره میشوند. برای ایجاد گروههای منطقی از اشیاء (objects) از سطلها (bucket) استفاده میشود. بهطور مثال، با استفاده از S3، کاربر ابتدا یک یا چند سطل ایجاد میکند و سپس اشیاء (فایلها) خود را در یکی از این سطلها قرار میدهد. یک سطل نمیتواند سطلهای دیگر را در خود جای دهد و یک فایل فقط میتواند در یک سطل وجود داشته باشد. این موضوع ممکن است محدودکننده به نظر برسد، اما اشیا دارای ابرداده (metadata) هستند و با استفاده از ابرداده، میتوانید همان سطح سازماندهی را که دایرکتوریها و زیرمجموعهها در یک سیستم فایل ارائه میدهند، شبیهسازی کنید.
همچنین، راهحلهای ذخیرهسازی اشیاء در صورت اجرا به عنوان یک خوشه توزیعشده عملکرد بهتری دارند. این موضوع قابلیت اطمینان و دسترسپذیری آنها را افزایش میدهد.
یکی از مزایای شاخص ذخیرهسازی اشیا، در ارتباط با مقیاسپذیری بالای آنها است. به دلیل فضای آدرسدهی تخت ذخیرهسازی پایهای (هر شیء فقط در یک سطل انجام میشود. همچنین، معماری فوق اجازه میدهد تا بهسرعت یک شی را در میان میلیاردها شی بالقوه پیدا کند. علاوه بر این، ذخیرهسازی اشیا در مقیاس تقریبا نامحدودی (پتابایت یا فراتر از آن) قرار دارند. همین مسئله باعث شده تا برای ذخیره مجموعه دادهها و مدیریت مدلهای زبانی بزرگ ایدهآل باشند.
بهترین گزینه ذخیرهسازی برای هوش مصنوعی
در نهایت، انتخاب گزینههای ذخیرهسازی برای هوش مصنوعی تحت تاثیر ترکیبی از الزامات، واقعیتها و ضروریات قرار میگیرند. با این حال، برای محیطهای تولیدی، دلایل محکمی برای استفاده از ذخیرهسازی اشیاء وجود دارد. دلایل این انتخاب به شرح زیر است:
عملکرد از منظر مقیاس: مخزنهای اشیا مدرن سریع هستند و حتی در مواجه با صدها پتابایت داده و درخواستهای همزمان همچنان سریع باقی میمانند. شما نمیتوانید با سایر گزینهها به چنین عملکردی دست پیدا کنید.
دادههای بدون ساختار: بسیاری از مجموعه دادههای یادگیری ماشین بدون ساختار هستند، مانند دادههای صوتی، تصویری و ویدئویی. حتی مجموعه دادههای جدولی که میتوانند در یک پایگاه داده رابطهای ذخیره شوند، در یک مخزن اشیاء راحتتر مدیریت میشوند. به عنوان مثال، برای یک مهندس رایج است که هزاران یا میلیونها ردیفی را که یک مجموعه آموزشی را تشکیل میدهند، به عنوان یک موجودیت واحد در نظر بگیرد که میتواند از طریق یک درخواست ساده ذخیره و بازیابی شود. همین مورد برای مجموعههای اعتبارسنجی و تست نیز صادق است.
رابطهای برنامهنویسی RESTful: این رابطها به استاندارد واقعی برای برقراری ارتباط بین سرویسها تبدیل شدهاند. در نتیجه، الگوهای پیامرسانی اثباتشدهای برای احراز هویت، مجوز، امنیت در انتقال و اعلانها وجود دارد.
رمزگذاری: اگر مجموعه دادههای شما شامل اطلاعات قابل شناسایی شخصی است، دادههای شما باید در حالت سکون رمزگذاری شوند.
سازگاری ابری (کوبرنتیس و کانتینرها): راهحلی که بتواند سرویسهای خود را در کانتینرهایی اجرا کند که توسط کوبرنتیس مدیریت میشوند، در تمام ابرهای عمومی اصلی قابل استفاده است. بسیاری از شرکتها دارای خوشههای داخلی کوبرنتیس هستند که میتوانند یک استقرار ذخیرهسازی اشیاء سازگار با کوبرنتیس را اجرا کنند.
غیرقابل تغییر (Immutable): قابلیت تکرار آزمایشها برای هوش مصنوعی بسیار مهم است و اگر دادههای زیرساختی جابجا شوند یا روی آنها بازنویسی صورت گیرد، امکان تکرار آنها وجود ندارد. علاوه بر این، محافظت از مجموعههای آموزشی و مدلها در برابر حذف، چه سهوی و چه عمدی، زمانی که شرکتها شروع به تنظیم مقررات هوش مصنوعی میکنند، به یک قابلیت اصلی برای یک سیستم ذخیرهسازی هوش مصنوعی تبدیل خواهد شد.
کدگذاری تصحیح خطا در مقابل RAID برای انعطافپذیری و دسترسپذیری دادهها: کدگذاری تصحیح خطا از درایوهای ساده برای ارائه افزونگی مورد نیاز برای ذخیرهسازی انعطافپذیر استفاده میکند. از طرف دیگر، آرایه رید (متشکل از یک کنترلر و چندین درایو) نوع دیگری از مکانیزم کنترلی است که باید مستقر و مدیریت شود. کدگذاری تصحیح خطا در سطح شی کار میکند، در حالی که رید در سطح بلوک کار میکند. اگر یک شی واحد خراب شود، کدگذاری تصحیح خطا میتواند آن شی را تعمیر کند و سیستم را به سرعت (در عرض چند دقیقه) به حالت کاملا عملیاتی بازگرداند. رید برای خواندن یا نوشتن هر دادهای نیاز به بازسازی کل حجم دارد و بازسازی بسته به اندازه درایو میتواند ساعتها یا روزها طول بکشد.
تعداد فایلهای مورد نیاز: بسیاری از کلان دادهها که برای آموزش مدلها استفاده میشوند، از میلیونها فایل کوچک تشکیل شدهاند. سازمانی را تصور کنید که دارای هزاران دستگاه اینترنت اشیا است که هر کدام هر ثانیه یک عملیات اندازهگیری را انجام میدهد. اگر هر اندازهگیری یک فایل باشد، پس با گذشت زمان، تعداد کل فایلها بیشتر از آن چیزی خواهد بود که یک سیستم فایلی توانایی مدیریت آنرا داشته باشد.
قابلیت جابهجایی در سراسر محیطها: یک مخزن اشیا نرمافزار-محور میتواند از یک فایل محلی، NAS، SAN و کانتینرهایی که با درایوهای NVMe در یک خوشه کوبرنتیس اجرا میشوند، به عنوان ذخیرهسازی پایهای خود استفاده کند. در نتیجه، در محیطهای مختلف قابل جابهجایی است و در همه جا از طریق رابط S3 در دسترس قرار میگیرد.
سخنی با متخصصان هوش مصنوعی و کارشناسان شبکه
امروزه، توسعهدهندگان و دانشمندان داده کنترل بیشتری روی محیطهای ذخیرهسازی خود دارند. روزهای کنترل شدید دسترسی به ذخیرهسازی توسط بخش فناوری اطلاعات سپری است. توسعهدهندگان به طور طبیعی به سمت فناوریهایی گرایش پیدا میکنند که نرمافزار-محور، متنباز، سازگار با ابر و ساده باشند. این ویژگیها اساسا ذخیرهسازی اشیا را به عنوان راهحل ایدهآل معرفی میکند.
اگر در حال راهاندازی یک ایستگاه کاری جدید با ابزارهای دلخواه یادگیری ماشین خود هستید، با نصب یک راهحل محلی، یک مخزن اشیا را به مجموعه ابزار خود اضافه کنید. همچنین، اگر سازمان شما دارای محیطهای رسمی برای آزمایش، توسعه، تست و تولید است، یک مخزن اشیا را به محیط آزمایشی خود اضافه کنید. این روش عالی برای معرفی فناوری جدید به تمام توسعهدهندگان در سازمان است. همچنین، میتوانید با استفاده از برنامه کاربردی واقعی که در محیط اجرا میشود، یکسری آزمایشها را انجام دهید. در صورت موفقیتآمیز بودن آزمایشها، برنامه کاربردی خود را در محیطهای نهایی مستقر کنید.
نویسنده: حمیدرضا تائبی
اشتراکگذاری
مطالب مشابه

