
7 الگوریتم یادگیری ماشین که هر دانشمند داده باید بداند

امنیت





فهرست مطالب
الگوریتم یادگیری ماشین
به عنوان یک دانشمند داده، از مهمترین و کلیدیترین مهارتهایی که باید در مورد آنها اطلاعات کاملی داشته باشید، SQL و زبان برنامهنویسی پایتون است، اما افزودن مهارت یادگیری ماشین به جعبه ابزارتان میتواند بسیار مفید باشد. این احتمال وجود دارد که به عنوان یک دانشمند داده همیشه از یادگیری ماشین استفاده نکنید، اما برخی از مسائل بهتر است با استفاده از انواع الگوریتم یادگیری ماشین به جای راهکارهای مبتنی بر قوانین برنامهنویسی حل شوند. در این مطلب از مفتاح رایانه افزار به شما الگوریتمهایی را معرفی خواهیم کرد که قدرتمند، کارآمد و پر کاربرد هستند و نقش مهمی در حل مسائل مختلف دارند.
در این مطلب، هفت الگوریتم یادگیری ماشین ساده، اما مفید را مورد بررسی قرار میدهیم و مرور کلی و مختصر بر الگوریتمها به همراه کارکرد و ملاحظات کلیدی آنها خواهیم داشت. همچنین، ایدههای کاربردی یا پروژههایی را پیشنهاد میکنیم که میتوانید با استفاده از کتابخانههایی همچون سایکیت-لرن (scikit-learn) بسازید.
۷ الگوریتم یادگیری ماشین
1. رگرسیون خطی
رگرسیون خطی یک روش آماری است که برای مدلسازی رابطه خطی بین یک متغیر وابسته (که میخواهیم آن را پیشبینی کنیم) و یک یا چند متغیر مستقل استفاده میشود. به عبارت سادهتر، رگرسیون خطی به ما کمک میکند با استفاده از یک خط مستقیم، رابطه بین متغیرها را توصیف کنیم و با داشتن مقدار متغیرهای مستقل، مقدار تقریبی متغیر وابسته را پیشبینی کنیم. این روش در بسیاری از زمینهها از جمله اقتصاد، علوم اجتماعی، و علوم طبیعی برای تحلیل دادهها و پیشبینی نتایج آینده به کار میرود. برای یک مدل رگرسیون خطی شامل n پیشبینیکننده، معادله به صورت زیر است:
در معادله مذکور، پارامترها به شرح زیر هستند:
Y: مقدار پیشبینی شده است.
Βi: ضرایب مدل هستند.
Xi: پیشبینیکنندهها هستند.
الگوریتم فوق، مجموع مربعات باقیمانده را برای یافتن مقادیر بهینه β به حداقل میرساند:
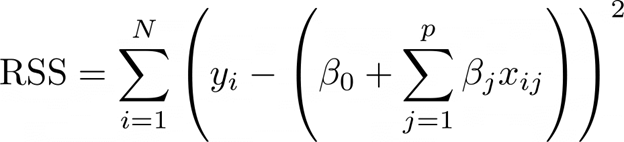
متغیرهای فرمول بالا به شرح زیر هستند:
N: تعداد مشاهدات است.
P: تعداد پیشبینیکنندهها است.
Βi: ضرایب هستند.
Xij: مقادیر پیشبینیکننده برای مشاهده i-ام و پیشبینیکننده j-ام هستند.
هنگامی که قصد استفاده از الگوریتم فوق را دارید، پیشنهاد میکنیم به یکسری ملاحظات کلیدی دقت کنید:
- توجه داشته باشید که الگوریتم فرض میکند رابطه خطی بین ویژگیها در مجموعه داده وجود دارد.
- مستعد همخطی و پرت بودن است.
برای آشنایی بهتر با عملکرد الگوریتم فوق، یک پروژه رگرسیون ساده در مورد پیشبینی قیمت خانه یک تمرین خوب است که پیشنهاد میکنم از انجام آن غافل نشوید.
2. رگرسیون لجستیک
رگرسیون لجستیک معمولا برای مشکلات طبقهبندی دودویی استفاده میشود، اما میتوان از آن برای طبقهبندی چند کلاسه نیز استفاده کرد. به بیان دقیقتر، برای پیشبینی احتمال وقوع یک رویداد دوگانه (موفقیت یا شکست، بله یا خیر) استفاده میشود. برخلاف رگرسیون خطی که برای پیشبینی متغیرهای پیوسته به کار میرود، رگرسیون لجستیک به ما کمک میکند تا احتمال وقوع یک رویداد خاص را بر اساس یک یا چند متغیر پیشبینیکننده تخمین بزنیم. به عنوان مثال، میتوان از رگرسیون لجستیک برای پیشبینی احتمال ابتلای یک بیمار به یک بیماری خاص بر اساس عوامل خطر مختلف استفاده کرد. نحوه کار الگوریتم فوق به شرح زیر است (لازم به توضیح است که رگرسیون لجستیک از تابع لجستیک (تابع سیگموئید) برای پیشبینی احتمالات استفاده میکند):
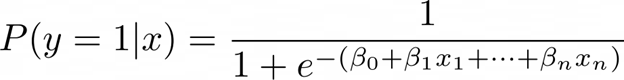
در معادله بالا، βi ضرایب مدل هستند. این تابع یک احتمال را به عنوان خروجی ارائه میدهد که میتواند برای اختصاص برچسبهای کلاس آستانهگذاری شود.
هنگامی که قصد استفاده از الگوریتم فوق را دارید به یکسری ملاحظات کلیدی به شرح زیر دقت کنید:
- مقیاسبندی ویژگی میتواند عملکرد مدل را بهبود بخشد.
- مشکل عدم تعادل کلاس را با تکنیکهایی مانند نمونهبرداری مجدد یا وزندهی برطرف کنید.
همانگونه که اشاره کردیم، رگرسیون لجستیک برای طیف وسیعی از وظایف طبقهبندی استفاده میشود. بهطور مثال، طبقهبندی و تفکیک یک ایمیل از اسپم، پروژه تقریبا سادهای است که نشان میدهد الگوریتم فوق به چه صورتی کار میکند.
3. درخت تصمیم
درخت تصمیم، مدلهای بصری هستند که برای طبقهبندی و رگرسیون استفاده میشوند. درخت تصمیم یک مدل پیشگویانه است که به صورت یک نمودار درختی برای نمایش تصمیمگیریهای متوالی و نتایج احتمالی آنها استفاده میشود. در این مدل، هر گره، نشاندهنده یک ارزیابی روی یک ویژگی است و هر شاخه نشاندهنده نتیجه است. برگهای درخت نیز نتایج نهایی یا پیشبینیهای مدل را نشان میدهند. درختهای تصمیم به دلیل سادگی، تفسیرپذیری بالا و قابلیت استفاده در مسائل طبقهبندی و رگرسیون بسیار محبوب هستند. این الگوریتمها کمک میکنند با تحلیل دادهها، تصمیمات بهتری بگیریم و روابط بین متغیرهای مختلف را بهتر درک کنیم. نحوه کار الگوریتم یادگیری ماشین فوق به این صورت است که الگوریتم ویژگی را انتخاب میکند که دادهها را بر اساس معیارهایی مانند ناخالصی جینی یا آنتروپی بهتر تقسیم میکند. این فرآیند ماهیت بازگشتی دارد.
آنتروپی: میزان بینظمی را در مجموعه داده اندازهگیری میکند.
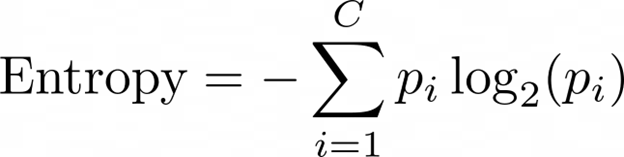
ناخالصی جینی: احتمال اشتباه در طبقهبندی یک نقطه انتخاب شده را اندازهگیری میکند.
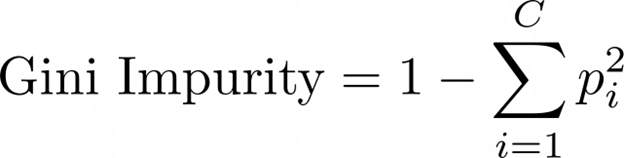
الگوریتم درخت تصمیم ویژگی را انتخاب میکند که منجر به کاهش ناخالصی میشود. هنگام استفاده از الگوریتم فوق به موارد زیر دقت کنید:
- ساده برای تفسیر، اما اغلب مستعد مشکل بیشبرازش است.
- میتواند دادههای دستهبندی شده و عددی را اداره کند.
برای درک بهتر عملکرد موضوع، میتوانید یک درخت تصمیم را روی یک مشکل طبقهبندی که قبلا روی آن کار کردهاید آموزش دهید و بررسی کنید که آیا عملکرد بهتری نسبت به رگرسیون لجستیک دارد یا خیر.
4. جنگلهای تصادفی
جنگلهای تصادفی یک روش یادگیری جمعی و مبتنی بر چند درخت تصمیم هستند که باهدف دستیابی به پیشبینیها، نتایج قویتر و دقیقتر مورد استفاده قرار میگیرد. جنگل تصادفی بر مبنای ترکیب تجمیع (تجمیع بوتاسترپ) و انتخاب ویژگی تصادفی، چند درخت تصمیم شکل میگیرد. در الگوریتم فوق، هر درخت یک حق رای دارد. بیشترین رای به عنوان پیشبینی نهایی در نظر گرفته میشود. الگوریتم جنگل تصادفی با میانگینگیری نتایج در بین درختان، مشکل بیشبرازش را کاهش میدهد. هنگام استفاده از الگوریتم فوق به ملاحظات کلیدی زیر دقت کنید:
- به خوبی با مجموعه دادههای بزرگ یا همان کلان دادهها کار میکند و بیشبرازش را کاهش میدهد.
- میتواند از نظر محاسباتی نسبت به یک درخت تصمیم منفرد پیچیدهتر باشد.
به عنوان یک تمرین، میتوانید الگوریتم جنگل تصادفی را برای یک پروژه پیشبینی ریزش مشتری اعمال کرده و نتایج را مورد بررسی قرار دهید.
5. ماشین بردار پشتیبان (SVM)
ماشین بردار پشتیبان یا SVM یک الگوریتم یادگیری ماشین یک نوع الگوریتم طبقهبندی است. این الگوریتم بهترین مرز ممکن بین دو گروه داده را پیدا میکند. این مرز طوری انتخاب میشود که بیشترین فاصله را از نزدیکترین دادههای هر گروه داشته باشد. به طور کلی، الگوریتم مذکور با این هدف مورد استفاده قرار میگیرد که بیشترین فاصله ممکن بین دو گروه داده را ایجاد کنیم و این کار را با استفاده از نقاطی که به این مرز نزدیکتر هستند انجام دهیم. این الگوریتم بر مبنای محاسبات ریاضی به شرح زیر تعریف میشود:
maximize w^T w
subject to yi(w^T xi + b) ≥ 1 for all i
در فرمول بالا، w بردار وزن، xi بردار ویژگی و yi برچسب کلاس است. هنگام استفاده از الگوریتم ماشین بردار پشتیبان به ملاحظات کلیدی به شرح زیر دقت کنید:
- میتوان ماشین بردار پشتیبان را برای دادههای غیرخطی قابل جداسازی استفاده کرد که تکنیک کرنل در این زمینه مفید است. کرنل، یک تکنیک ریاضی است که به SVM اجازه میدهد تا دادههای غیرخطی را به یک فضای با ابعاد بالاتر نگاشت کند و در آنجا به صورت خطی جداسازی کند.
- الگوریتم حساس به انتخاب تابع کرنل است. تابع کرنل، تابعی است که شباهت بین دو نقطه داده را اندازهگیری میکند. انتخاب تابع کرنل مناسب میتواند به طور قابل توجهی عملکرد SVM را تحت تاثیر قرار دهد.
- نیاز به حافظه و قدرت محاسباتی قابل توجهی برای کلان دادهها دارد.
- SVM برای پردازش کلان دادهها به منابع محاسباتی زیادی نیاز دارد.
اگر علاقهمند به آزمایش الگوریتم SVM هستید، میتوانید برای مسائل طبقهبندی متن، مانند تشخیص اسپم یا طبقهبندی احساسات از آن استفاده کنید. البته، همانگونه که اشاره کردیم در ارتباط با کلان دادهها به حافظه اصلی و قدرت محاسباتی بالایی نیاز دارید.
6. نزدیکترین کا همسایگی (KNN) سرنام K-Nearest Neighbors
K-Nearest Neighbors یا بهاختصار KNN، یک الگوریتم ساده و غیر پارامتریک است که برای طبقهبندی و رگرسیون با یافتن کا نزدیکترین نقطه به نمونه محاوره استفاده میشود. نحوه کار الگوریتم فوق به این صورت است که الگوریتم فاصله (مانند اقلیدسی) بین نقطه تعیین شده در محاوره و تمام نقاط دیگر در مجموعه داده را محاسبه میکند، سپس کلاسی که اکثریت همسایگان به آن نزدیک هستند را انتخاب میکند. برای درک بهتر و دقیقتر موضوع، به مثال زیر دقت کنید:
فرض کنید میخواهیم بدانیم یک میوه جدید به کدام گروه، سیب یا پرتقال، تعلق دارد. الگوریتم فاصله بین این میوه جدید و تمام سیبها و پرتقالهای موجود را محاسبه میکند. سپس، نزدیکترین میوهها به میوه جدید را پیدا میکند. اگر اکثریت میوهها، نزدیک سیب باشند، الگوریتم میوه جدید را نیز به گروه سیبها اختصاص میدهد. هنگامی که قصد استفاده از الگوریتم فوق را دارید به ملاحظات کلیدی به شرح زیر دقت کنید:
- انتخاب k و متریک فاصله میتواند به طور قابل توجهی عملکرد را تحت تاثیر قرار دهد.
- این الگوریتم به شدت تحت تاثیر مسائلی قرار میگیرد که در فضاهای بسیار بزرگ و پیچیده با تعداد ابعاد زیاد وجود دارد. این مسائل شبیه به مشکل سنجش فاصله بین دو نقطه در فضایی هستند که به دلیل پیچیدگی فضا، محاسبهی دقیق آنها بسیار دشوار است.
اگر تمایل به آزمودن الگوریتم فوق دارید، روی یک مسئله ساده طبقهبندی کار کنید تا عملکرد KNN در مقایسه با دیگر الگوریتمهای طبقهبندی را مشاهده کنید.
7. خوشهبندی K-Means
K-Means یک الگوریتم یادگیری ماشین بدون نظارت است که برای تقسیم دادهها به K گروه یا خوشه مجزا استفاده میشود. در این الگوریتم، هر داده به خوشهای که مرکز آن نزدیکترین فاصله را به آن داده دارد، اختصاص داده میشود. این مراکز خوشهای به صورت تصادفی انتخاب میشوند و به طور مسمتمر بهروز میشوند تا مجموع مربعات فاصله هر داده تا مرکز خوشه به حداقل برسد. K-Means یک روش ساده و موثر برای شناسایی الگوهای پنهان در دادهها و گروهبندی دادههای مشابه با هم است. الگوریتم بر مبنای دو مرحله زیر تکرار میشود:
- اختصاص هر نقطه داده به نزدیکترین مرکز خوشه.
- بهروزرسانی مرکز خوشهها بر اساس میانگین نقاط اختصاصیافته به آنها.
همچنین، توجه داشته باشید که الگوریتم K-means مجموع مربعات فواصل را بر مبنای فرمول زیر به حداقل میرساند:
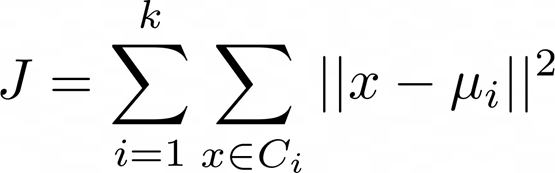
در فرمول بالا، μi مرکز خوشه Ci است. هنگام استفاده از الگوریتم فوق به ملاحظات کلیدی مهم زیر دقت کنید:
- نسبتا حساس به انتخاب اولیه تصادفی مرکز خوشهها است.
- الگوریتم به پرت بودن حساس است.
- نیاز به تعریف قبلی k دارد که ممکن است همیشه واضح نباشد.
یک پروژه خوب که اجازه میدهد قدرت خوشهبندی K-means را مشاهده کنید، بخشبندی مشتریان یا فشردهسازی تصویر از طریق کوانتیزاسیون رنگ است.
نویسنده: حمیدرضا تائبی
اشتراکگذاری
مطالب مشابه

