ایامدی در جریان برگزاری کنفرانس Hot Chips 2024 از تراشه AMD MI300X رونمایی کرد. تراشه MI300X یا به عبارت کاملتر، تراشه GPU AMD Instinct MI300X CDNA 3 با هدف پاسخگویی به نیازهای شرکتها در ارتباط با هوش مصنوعی طراحی شده و مجهز به 320 واحد محاسباتی بر روی یک تراشه کامل است. AMD MI300X سومین نسل از شتابدهندههای Instinct است که برای انجام محاسبات هوش مصنوعی طراحی شده است. این تراشه در نسخه MI300A نیز عرضه میشود که یک محصول بهینهسازی شده برای انجام فرامحاسبات-APU است و ترکیبی از هستههای Zen 5 در دو چیپلت را مورد استفاده قرار میدهد، در حالی که بقیه از هستههای GPU CDNA 3 استفاده میکنند.
ایامدی، در کنفرانس امسال، جزییات بیشتری در ارتباط با تراشه Instinct MI300X ارائه کرد که در نوع خود یک شتابدهنده محاسباتی کاملا قدرتمند و پیشرفته به شمار میرود. برای شروع، باید بگوییم که AMD Instinct MI300X دارای مجموع 153 میلیارد ترانزیستور است که ترکیبی از گرههای 6nm FinFET process و TSMC 5nm را ارائه میدهد.
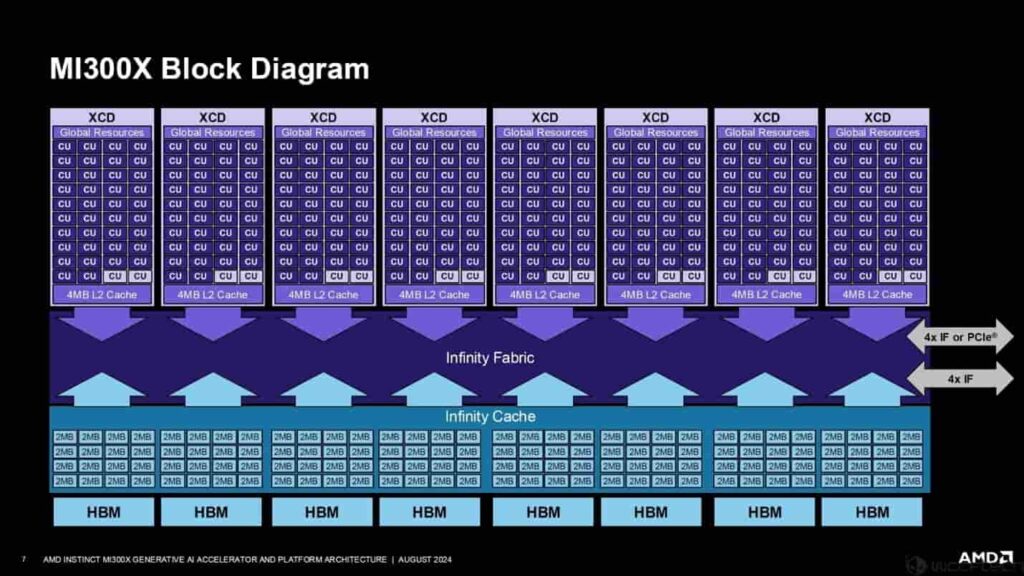
در معماری مذکور، هشت چپلت دارای چهار موتور مشترک هستند و هر موتور مشترک دارای 10 واحد محاسباتی است. کل تراشه دارای 40 موتور سایهزن در یک XCD منفرد است. هر XCD دارای حافظه نهان L2 اختصاصی مخصوص به خود است و حاشیههای تراشه دارای Infinity Fabric Link، 8 سایت ورودی/خروجی HBM3 و یک لینک PCIe Gen 5.0 منفرد با پهنای باند 128 گیگابایت/ثانیه است که MI300X را به یک پردازنده AMD EPYC متصل میکند.
ایامدی از نسل چهارم Infinity Fabric در تراشه Instinct MI300X خود استفاده میکند که پهنای باند 896 گیگابایت بر ثانیه را ارائه میدهد. همچنین، این تراشه شامل یک لینک Infinity Fabric Advanced Package است که تمام تراشهها را با پهنای باند 4.8 ترابایت بر ثانیه به شکل دوطرفه به یکدیگر متصل میکند، در حالی که اینترفیس XCD/IOD دارای پهنای باند 2.1 ترابایت/ثانیه است.
هنگامی که معماری CDNA 3 را به شکل دقیق مورد بررسی قرار دهیم به اطلاعات زیر دست پیدا میکنیم:
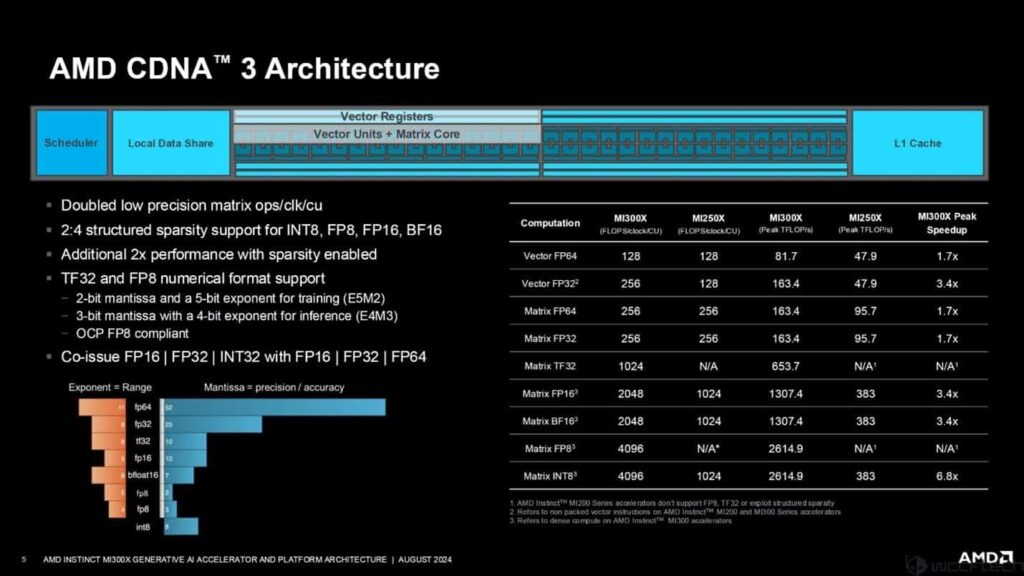
دو برابر شدن عملیات ماتریسی با دقت کم در هر ساعت و هر واحد محاسباتی
پشتیبانی از ساختار متراکم 2:4 برای INT8، FP8، FP16، BF16
2 برابر عملکرد بهتر به لطف ساختار متراکم
پشتیبانی از فرمت عددی TF32 و FP8
توانایی رسیدگی همزمان به محاسبات FP16/FP32/INT32 با FP16/FP32/FP64
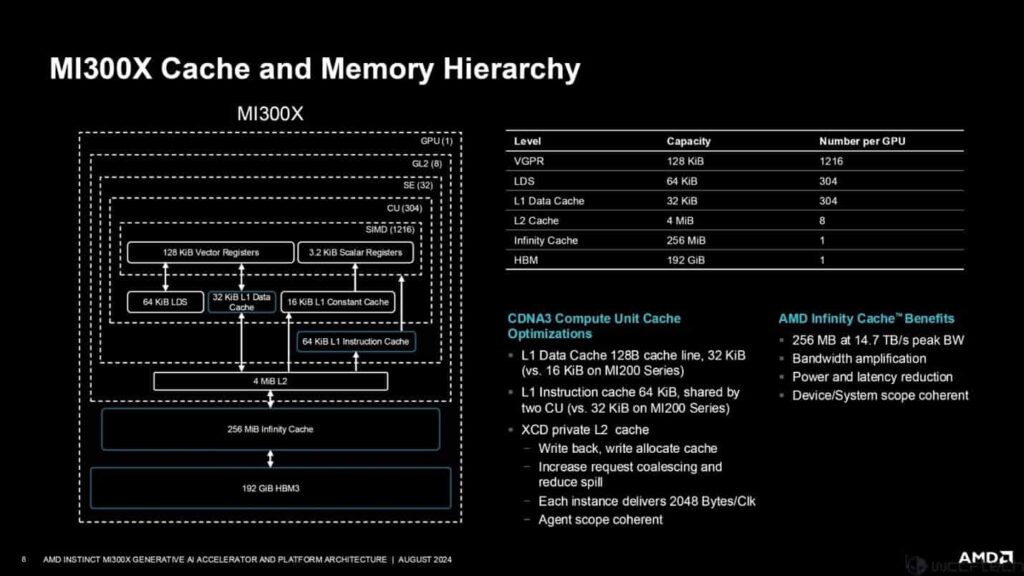
شکل زیر معماری Mi300X را نشان میدهد. همانگونه که مشاهده میکنید هر XCD دارای دو واحد محاسباتی غیرفعال است. تراشه کامل با 20480 هزار هسته و MI300X با 19456 هسته پیکربندی شده است. همچنین، 256 مگابایت حافظه کش اختصاصی Infinity روی تراشه وجود دارد.
هر واحد محاسباتی CDNA از یک مدار زمانبندیکننده، حافظه اشتراکی محلی، رجیسترهای برداری، واحدهای برداری، هسته ماتریسی و حافظه کش L1 تشکیل شده است. عملکرد تراشه MI300X در مقایسه با تراشه MI250X به شرح زیر است:
7 برابر سریعتر از MI250X در Vector FP64
4 برابر سریعتر از MI250X در Vector FP32
7 برابر سریعتر از MI250X در Matrix FP64
7 برابر سریعتر از MI250X در Matrix FP32
4 برابر سریعتر از MI250X در Matrix FP16
4 برابر سریعتر از MI250X در Matrix BF16
8 برابر سریعتر از MI250X در Matrix INT8
این ارقام نشان میدهند که MI300X در عملیات مختلف محاسباتی، به طور قابل توجهی سریعتر از نسل قبلی خود، یعنی MI250X است.
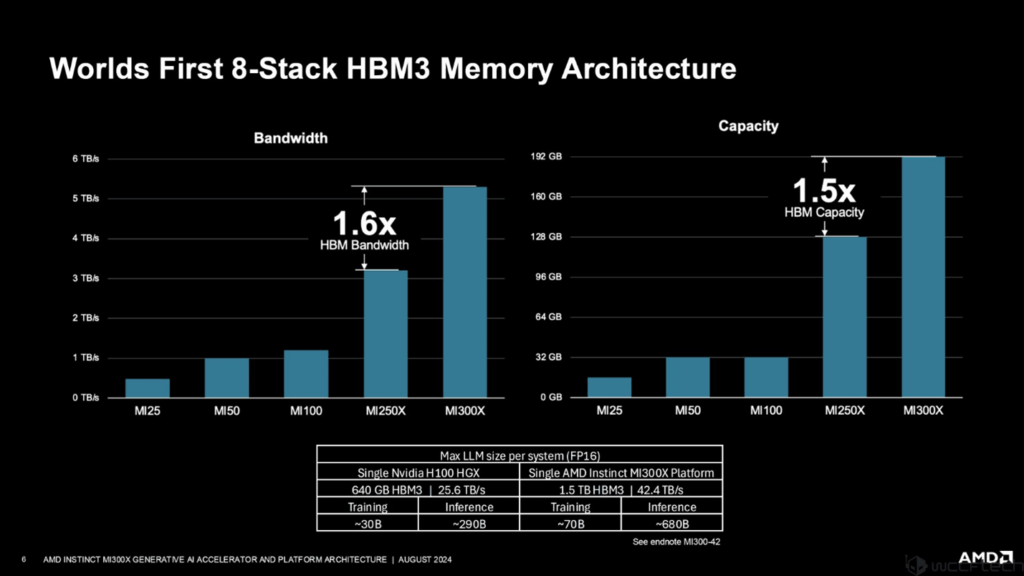
AMD Instinct MI300X اولین شتابدهندهای است که از حافظه 8 لایهای HBM3 استفاده میکند. این طراحی جدید، ظرفیت حافظه را تا 1.5 برابر افزایش داده و با استفاده از استاندارد HBM3، پهنای باند را نیز 1.6 برابر نسبت به نسل قبل (MI250X) بهبود بخشیده است. به عبارت دیگر، این تراشه میتواند دادهها را بسیار سریعتر و با حجم بیشتری جابهجا کند. این ویژگیها باعث میشوند MI300X برای انجام محاسبات پیچیده، به ویژه در حوزه هوش مصنوعی، بسیار مناسب باشد. انودیا نیز اواخر امسال با معرفی GPUهای Blackwell قصد دارد از این فناوری حافظه استفاده کند. این پیشرفتها در ارتباط با حافظه نشان میدهند که MI300X از نظر ظرفیت و سرعت دسترسی به دادهها، نسبت به نسل قبلی خود بهبود قابل توجهی داشته است.
همچنین، ایامدی ادعا میکند که MI300X میتواند مدلهای زبانی بزرگتری را نسبت به رقیب خود، NVIDIA HGX H100، پردازش کند. به لطف حافظه بیشتر و سریعتر، MI300X قادر است مدلهایی با اندازه بسیار بزرگتر را آموزش دهد. این حرف به معنای آن است که MI300X میتواند از فرآیند آموزش مدلهای پیچیدهتر و قدرتمندتری پشتیبانی کند که قابلیتهای بیشتری در ارتباط با ترجمه زبانی، تولید متن خلاقانه و پاسخگویی دقیق به سوالات ارائه میدهند.
یکی دیگر از ویژگیهای جالب Instinct Mi300X تقسیمبندی فضایی AMD است که به کاربران اجازه میدهد تا XCDها را مطابق با نیازهای بار کاری خود تقسیمبندی کنند. همه XCDها به عنوان یک پردازنده واحد کار میکنند، اما میتوانند تقسیمبندی و گروهبندی شوند تا به عنوان چندین GPU ظاهر شوند. لازم به توضیح است که XCD واحدهای محاسباتی در تراشه MI300X هستند، در حالی که بخشبندی فضایی به معنای تقسیمبندی تراشه به بخشهای کوچکتر است.
ایامدی، در ماه اکتبر پلتفرم Instinct خود را با MI325X ارتقا خواهد داد که دارای حافظه HBM3e و ظرفیتهای افزایش یافته تا 288 گیگابایت خواهد بود. برخی از ویژگیهای MI325X به شرح زیر هستند:
2x Memory
3x Memory Bandwidth
3x Peak Theoretical FP16
3x Peak Theoretical FP8
2x Model Size per Server
با توجه به توضیحاتی که ارائه کردیم باید بگوییم که پاسخ انودیا سال آینده با Blackwell Ultra با 288 گیگابایت HBM3e خواهد بود. بنابراین، ایامدی بار دیگر در این بازار کلیدی در حوزه هوش مصنوعی پیشتاز خواهد بود. بنابراین، تراشههای ساخت این شرکت در ارتباط با آموزش مدلهای زبانی بزرگ که شامل میلیاردها یا تریلیونها پارامتر خواهند بود و به حافظههای زیادی نیاز خواهند داشت، مشتریان خود را خواهند داشت.